
动漫设计开发师
在D3D中,为什么采用顶点缓存来存储顶点而不采用数组()。A、因为对数组的使用比较麻烦B、因为数组所占用的存储空间较大C、因为顶点缓存可以被存放在显存中D、因为顶点缓存可以被放置在系统主存储区中
题目
在D3D中,为什么采用顶点缓存来存储顶点而不采用数组()。
- A、因为对数组的使用比较麻烦
- B、因为数组所占用的存储空间较大
- C、因为顶点缓存可以被存放在显存中
- D、因为顶点缓存可以被放置在系统主存储区中
相似问题和答案
第1题:
A、一维数组,一维数组
B、二维数组,一维数组
C、二维数组,二维数组
D、一维数组,二维数组
第2题:
下面关于图的存储的叙述中正确的是()。
A.用邻接表法存储图,占用的存储空间大小只与图中边数有关,而与顶点个数无关
B.用邻接表法存储图,占用的存储空间大小与图中边数和顶点个数都有关
C.用邻接矩阵法存储图,占用的存储空间大小与图中顶点个数和边数无关
D.用邻接矩阵存储图,占用的存储空间大小只与图中边数有关,而与顶点个数无关
第3题:
阅读下列函数说明和C函数,将应填入(n)处的字句写在对应栏内。[说明]
邻接表是图的一种顺序存储与链式存储结合的存储方法。其思想是:对于图G中的每个顶点 vi,将所有邻接于vi的顶点vj连成一个单链表,这个单链表就称为顶点vi的邻接表,其中表头称作顶点表结点VertexNode,其余结点称作边表结点EdgeNode。将所有的顶点表结点放到数组中,就构成了图的邻接表AdjList。邻接表表示的形式描述如下: define MaxVerNum 100 /*最大顶点数为100*/
typedef struct node{ /*边表结点*/
int adjvex; /*邻接点域*/
struct node *next; /*指向下一个边表结点的指针域*/ }EdgeNode;
typedef struct vnode{ /*顶点表结点*/
int vertex; /*顶点域*/
EdgeNode *firstedge; /*边表头指针*/
}VertexNode;
typedef VertexNode AdjList[MaxVerNum]; /*AdjList是邻接表类型*/
typedef struct{
AdjList adjlist; /*邻接表*/
int n; /*顶点数*/
}ALGraph; /*ALGraph是以邻接表方式存储的图类型*/
深度优先搜索遍历类似于树的先根遍历,是树的先根遍历的推广。
下面的函数利用递归算法,对以邻接表形式存储的图进行深度优先搜索:设初始状态是图中所有顶点未曾被访问,算法从某顶点v出发,访问此顶点,然后依次从v的邻接点出发进行搜索,直至所有与v相连的顶点都被访问;若图中尚有顶点未被访问,则选取这样的一个点作起始点,重复上述过程,直至对图的搜索完成。程序中的整型数组visited[]的作用是标记顶点i是否已被访问。
[函数]
void DFSTraverseAL(ALGraph *G)/*深度优先搜索以邻接表存储的图G*/
{ int i;
for(i=0;i<(1);i++) visited[i]=0;
for(i=0;i<(1);i++)if((2)) DFSAL(G,i);
}
void DFSAL(ALGraph *G,int i) /*从Vi出发对邻接表存储的图G进行搜索*/
{ EdgeNode *p;
(3);
p=(4);
while(p!=NULL) /*依次搜索Vi的邻接点Vj*/
{ if(! visited[(5)]) DFSAL(G,(5));
p=p->next; /*找Vi的下一个邻接点*/
}
}
(1) G->n (2) ! visited[i] (3) visited[i]=1 (4) G->adjlist[i].firstedge (5) p->adjvex 解析:(1)此处循环是访问标志向量的初始化,应遍历 G的全体点,共计G→n个;
(2)若Vi未被访问,则从Vi开始搜索;
(3)标记Vi已访问;
(4)为递归搜索Vi的邻接点,需先取出Vi边表的头指针;
(5)若Vi的邻接点p->adjvex尚未被访问,则从它出发进行纵深搜索。
第4题:
在索引缓存中定位顶点也就是在顶点缓存中定位顶点。
正确答案:正确
第5题:
第6题:
此题为判断题(对,错)。
第7题:
图的深度优先遍历算法中需要设置一个标志数组,以便区分图中的每个顶点是否被访问过。
此题为判断题(对,错)。
第8题:
以下说法正确的有()。
A、使用ReDim语句将释放动态数组所占的存储空间
B、使用ReDim语句也可以保留动态数组中原有的内容
C、使用Erase语句将释放动态数组所占的存储空间
D、使用Erase语句将释放静态数组所占的存储空间
第9题:
B.进行广度优先遍历运算所消耗的时间与采用哪一种存储结构无关
C.采用邻接表表示图时,查找所有顶点的邻接顶点的时间复杂度为O(n*e)
D.进行深度优先遍历运算所消耗的时间与采用哪一种存储结构无关
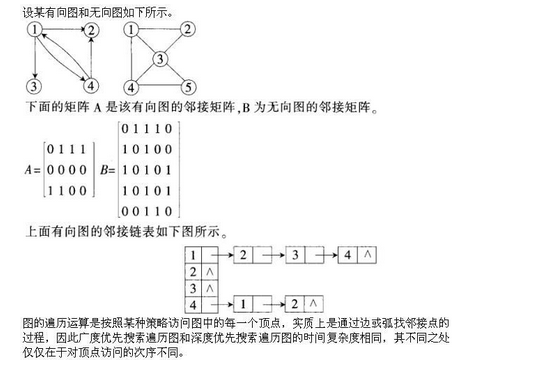
第10题:
如果要对Mesh进行优化,需要知道Mesh的三角形的邻接信息情况,这些信息存储在()中。
- A、邻接矩阵
- B、邻接缓存
- C、深度缓存
- D、邻接数组
正确答案:D