
数据库应用技术
您要对EMPLOYEES表的FIRST_NAME和LAST_NAME列创建一个组合索引。以下哪条语句将完成此任务()A、CREATE INDEXfl_idx ON employees(first_name last_name)B、CREATE INDEXfl_idx ON employees(first_name),employees(last_name)C、CREATE INDEXfl_idx ON employees(first_name,last_name)D、CREATE INDEXfl_idx
题目
您要对EMPLOYEES表的FIRST_NAME和LAST_NAME列创建一个组合索引。以下哪条语句将完成此任务()
- A、CREATE INDEXfl_idx ON employees(first_name last_name)
- B、CREATE INDEXfl_idx ON employees(first_name),employees(last_name)
- C、CREATE INDEXfl_idx ON employees(first_name,last_name)
- D、CREATE INDEXfl_idx ON employees(first_name);CREATE INDEXfl_idx ON employees(last_name)
相似问题和答案
第1题:
Examine the structure of the EMPLOYEES table:Column name Data type RemarksEMPLOYEE_ID NUMBER NOT NULL, Primary KeyLAST_NAME VARCNAR2(30)FIRST_NAME VARCNAR2(30)JOB_ID NUMBERSAL NUMBERMGR_ID NUMBER References EMPLOYEE_ID column DEPARTMENT_ID NUMBERYou need to create an index called NAME_IDX on the first name and last name fields of the EMPLOYEES table. Which SQL statement would you use to perform this task? ()
A. CREATE INDEX NAME _IDX (first_name, last_name);
B. CREATE INDEX NAME _IDX (first_name, AND last_name)
C. CREATE INDEX NAME_IDX ON (First_name, last_name);
D. CREATE INDEX NAME_IDX ON employees (First_name, AND last_name);
E. CREATE INDEX NAME_IDX ON employees (First_name, last_name);
F. CREATE INDEX NAME_IDX FOR employees (First_name, last_name);
第2题:
已知下列员工关系表。Employees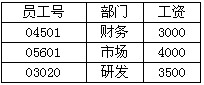 对该表的工资属性和完整性约束为:2000≤工资≤5000 现将如下2个操作组织为事务T,操作1先执行,操作2后执行。 操作1:INSERT INTO Employees VALUES(‘03650’,‘研发’,‘4600’) 操作2:UPDATE Employees SET工资=工资1.2 WHERE部门=‘市场OR部门=研发’事务T执行完毕后,关系表Employees.的数据是
对该表的工资属性和完整性约束为:2000≤工资≤5000 现将如下2个操作组织为事务T,操作1先执行,操作2后执行。 操作1:INSERT INTO Employees VALUES(‘03650’,‘研发’,‘4600’) 操作2:UPDATE Employees SET工资=工资1.2 WHERE部门=‘市场OR部门=研发’事务T执行完毕后,关系表Employees.的数据是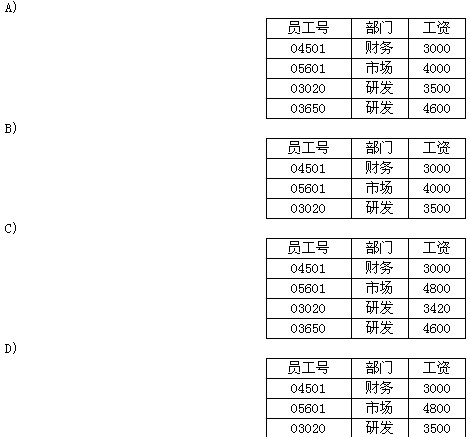
B 解析:事务中的操作,要么都成功,要么都失败。在数据更新时,将工资乘以1.2,4600*1.2=5520>5000,不满足完整性约束,显然操作2在针对(“03560”,“研发”,4600) 时会失败,则整个操作全部失败,数据将不会修改,故选B。
第3题:
A.没有给表employees和表departments加别名
B.没有给列department_id加别名
C.不能用employees.department_id=departments.department_id作为条件
D.SELECT后面的department_id没有指定是哪个表
第4题:
“雇员”表在LAST_NAME列上有一个名为LN_IDX的索引。您要将此索引更改为FIRST_NAME列的索引。以下哪条SQL语句将实现此操作()
- A、ALTER INDEX ln_idx ON employees(first_name)
- B、ALTER INDEX ln_idx TO employees(first_name)
- C、ALTER INDEX ln_idx TO fn_idx ON employees(first_name)
- D、以上都不能;您无法变更索引
正确答案:B
第5题:
数据集中的数据表名称是不区分大小写的,ds.Tables("Employees")和ds.Tables("employees")是同一个表。
正确答案:错误
第6题:
在SQL Server 2000中,现要在employees表的first_name和last_name列上建立一个唯一的非聚集复合索引,其中first_name列数据的重复率是5%,last_name列数据的重复率是10%。请补全下列语句使以first_name和last_name列作为条件的查询效率最高。
CREATE UNIQUE NONCLUSTERED INDEX Idx_Name
ON employees(______)
first_nameASC,last_nameDESC
第7题:
数据库benet中有个员工表employees,该表中有职务列,可以实现检查哪些员工的信息中没有填写职务一栏,应该使用子句()
- A、Select*from employees where职务=NULL
- B、Select*from employees where职务=’NULL’
- C、Select*from employees where职务ISNULL
- D、Select*from employees where职务IS‘NULL’
正确答案:C
第8题:
A.Select*from employees where职务=NULL
B.Select*from employees where职务=‘NULL’
C.Select*from employees where职务ISNULL
D.Select*from employees where职务IS‘NULL’
第9题:
数据集中的数据表名称是区分大小写的,ds.Tables("Employees")和ds.Tables("employees")不是同一个表。
正确答案:正确
第10题:
在执行语句SELECT department_id FROM employees,departments WHERE employees.department_id= departments.department_id;时报错,原因是()。
- A、没有给表employees和表departments加别名
- B、没有给列department_id加别名
- C、不能用employees.department_id=departments.department_id作为条件
- D、SELECT后面的department_id没有指定是哪个表
正确答案:D