
Java程序设计
单选题()类的对象代表的是XML文档中的标签元素,此类继承于Node,也是Node的主要子类。A AttributeB ElementC NodelistD attr
题目
Attribute
Element
Nodelist
attr
参考答案和解析
相似问题和答案
第1题:
A.Node和Element类
B.Document和NodeList类
C.TransformerFactory和Transformer类
D.TransFactory和Transmer类
第2题:
函数Node *difference(A,B)用于求两个集合之差C=A-B,即当且仅当e是A中的一个元素,但不是B中的元素时,e是C中的元素。集合用有序链表实现,用一个空链表表示一个空集合,表示非空集合的链表根据元素之间按递增排列。执行C=A-B之后,表示集合A和B的链表不变,若结果集合C非空,则表示其链表根据元素之值按递增排列。函数append()用于在链表中添加节点。
[C函数]
typedef struct node{
int element;
struct node *link;
}Node;
Node *A,*B,*C;
Node *append(last,e)
Node *last;
int e;
{last->link=(Node *)malloc(sizeof(Node));
last->link->element=e;
return(last->link);
}
Node *difference(A,B)
Node *A,*B;
{ Node *c,*last;
C=last=(Node *)malloc(sizeof(Node));
while( (1) )
if(A->element<B->element){
last=append(last,A->element);
A=A->link:
}
else if( (2) ){
A:A->link;
B:B->link;
}
elSe
(3) ;
while( (4) ){
last=append(last,A->element);
A=A->link:
}
(5) ;
last=c;
c=c->link;
free(last);
return(c);
}
(1) B->link (2) A->element==B->element (3) B=B->link (4) A>link!=NULL (5) last->link=NULL 解析:本题用链表表示集合,通过比较链表的元素值判断集合的元素之间的关系。第一个while循环的条件是链表B指针不指向空,即空(1)应填“B->link”。由于A,B两集合都是按递增排列的,则如果A中的元素小于B中的元素,A中元素直接放入集合C中,集合A指向其下一个元素;如果A中的元素等于B中的元素,集合A,B分别指向下一个元素,即空(21填“A->element==B->element”;如果A中的元素大于B中的元素,集合B指向其下一个元素,即空(3)填“B=B->link”。第二个循环的条件是链表A指针不指向空时,将A中元素直接加入到C中,即空(4)填“A->link!=NULL”。将链表C最后节点指针指向空,即空(51填“last->link=NULL”。
第3题:
有以下程序段
typedef struct node { int data; struct node *next; } *NODE;
NODE p;
以下叙述正确的是
A)p 是指向 struct node 结构变量的指针的指针
B)NODE p ;语句出错
C)p 是指向 struct node 结构变量的指针
D)p 是 struct node 结构变量

第4题:
阅读以下说明和C语言函数,将应填入(n)。
【说明】
已知包含头结点(不存储元素)的单链表的元素已经按照非递减方式排序,函数 compress(NODE*head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。
处理过程中,当元素重复出现时,保留元素第一次出现所在的结点。
图2-1(a)、(b)是经函数compress()处理前后的链表结构示例图。
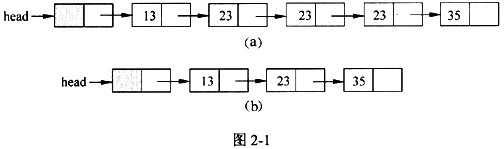
链表的结点类型定义如下:
typedef struct Node{
int data;
struct Node *next;
}NODE;
【C语言函数】
void compress(NODE *head)
{ NODE *ptr,*q;
ptr= (1); /*取得第一个元素结点的指针*/
while( (2)&& ptr->next) {
q=ptr->next;
while(q&&(3)) { /*处理重复元素*/
(4)q->next;
free(q);
q=ptr->next;
}
(5) ptr->next;
}/*end of while */
}/*end of compress*/
(1)head->next (2)ptr (3)q->data == ptr->data 或ptr->next->data==ptr->data,或其等价表示 (4)ptr->next (5)ptr 解析:本题考查基本程序设计能力。
链表上的查找、插入和删除运算是常见的考点。本题要求去掉链表中的重复元素,使得链表中的元素互不相同,显然是对链表进行查找和删除操作。
对于元素已经按照非递减方式排序的单链表,删除其中重复的元素,可以采用两种思路。
1.顺序地遍历链表,对于逻辑上相邻的两个元素,比较它们是否相同,若相同,则删除后一个元素的结点,直到表尾。代码如下:
ptr=head->next;/*取得第一个元素结点的指针*/
while(ptr && ptr->next){ /*指针ptr指示出重复序列的第一个元素结点*/
q=ptr->next;
while(q && ptr->data==q->data){/*处理重复元素*/
ptr->next=q->next;/*将结点从链表中删除*/
free(q);
q=ptr->next; /*继续扫描后继元素*/
}
ptr=ptr->next;
}
2.对于每一组重复元素,先找到其中的第一个结点,然后向后查找,直到出现一个相异元素时为止,此时保留重复元素的第一个结点,其余结点则从链表中删除。
ptr=head->next;/*取得第一个元素结点的指针*/
while(ptr && ptr->next){/*指针ptr指示出重复序列的第一个元素结点*/
q=ptr->next;
while(q && ptr->data==q->data) /*查找重复元素*/
q=q->next;
s=ptr->next; /*需要删除的第一个结点*/
ptr->next=q; /*保留重复序列的第一个结点,将其余结点从链表中删除*/
while(s && s!=q}{/*逐个释放被删除结点的空间*/
t = s->next;free(s);s = t;
}
ptr=ptr->next;
}
题目中采用的是第一种思路。
第5题:
阅读以下技术说明和Java代码,将Java程序中(1)~(5)空缺处的语句填写完整。
[说明]
类Queue表示队列,类中的方法如表4-12所示。

类Node表示队列中的元素;类EmptyQueueException给出了队列中的异常处理操作。
[Java代码]
public class testmain { //主类
public static viod main (string args[]) {
Queue q= new Queue;
q.enqueue("first!");
q.enqueue("second!");
q.enqueue("third!");
(1) {
while(true)
system.out.println(q.dequeue());
}
catch( (2) ) { }
}
public class Queue { //队列
node m_firstnode;
public Queue(){m_firstnode=null;}
public boolean isempty() {
if (m_firstnode= =null)
return true;
else
return false;
}
public viod enqueue(object newnode) { //入队操作
node next = m_firstnode;
if (next = = null) m_firstnode=new node(newnode);
else {
while(next.getnext() !=null)
next=next.getnext();
next.setnext(new node(newnode));
}
}
public object dequeue() (3) { //出队操作
object node;
if (is empty())
(4)
else {
node =m_firstnode.getobject();
m_firstnode=m_firstnode.getnext();
return node;
}
}
}
public class node{ //队列中的元素
object m_data;
node m_next;
public node(object data) {m_data=data; m_next=null;}
public node(object data,node next) {m_data=data; m_next=next;}
public void setobject(object data) {m_data=data; }
public object getobject(object data) {return m_data; }
public void setnext(node next) {m_next=next; }
public node getnext() {return m_next; }
}
public class emptyqueueexception extends (5) { //异常处理类
public emptyqueueexception() {
system. out. println ( "队列已空!" );
}
}
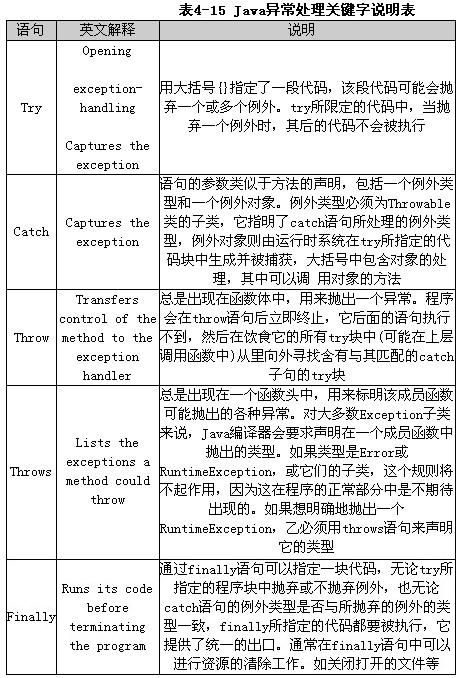 Java运行时系统要求方法必须捕获或者指定它可以抛出的所有被检查的异常如表4-16所示。
Java运行时系统要求方法必须捕获或者指定它可以抛出的所有被检查的异常如表4-16所示。
 try块和catch块是异常处理器的两个组件。在try块中产生的异常通常被紧跟其后的catch块指定的处理器捕获。
try {
可能抛出异常的语句
}
catch(异常类型 异常引用) {
处理异常的语句
}
catch语句可以有多个分别处理不同类的例外。Java运行时系统从上到下分别对每个catch语句处理的例外类型进行检测直到找到类型相匹配的catch语句为止。其中类型匹配是指catch所处理的例外类型与生成的例外对象的类型完全一致或者是它的父类因此catch语句的排列顺序应该是从特殊到一般。也可以用一个catch语句处理多个例外类型此时它的例外类型参数应该是这几个例外类型的父类程序设计中要根据具体的情况来选择catch语句的例外处理类型。
在选择要抛出的异常的类型时可以使用其他人编写的异常类也可以编写自己的异常类。本试题中采用自定义的类作为异常的类型。
仔细阅读试题中给出的Java源代码可知主类TestMain包含了异常处理机制用于检测在出队时“队列为空”的错误。因此(1)空缺处所填写的内容是“try”。
由catch语句的语法可知(2)空缺处所填写的内容是对相应异常类型的引用。结合试题中给出的关键信息“类EmptyQueueException给出了队列操作中的异常处理操作”即类EmptyQueueException是进行异常处理的类因此(2)空缺处所填写的内容是“EmptyQueueExceptione”或者“Exceptione”其中e是对象名可用任意合法标识符替换。
由于异常都是从超类Exception派生而来的因此(5)空缺处所填写的内容是“Exception”。
仔细阅读主类TestMain程序段可以看到在try块的内部并没有给出显示的抛出异常语句即没有出现throw语句。结合(4)空缺处所在行的注释—“队列为空抛出异常”可以推断在类Queue的方法dequeue中必定要抛出异常。因此(3)空缺处应指定方法dequeue可以抛出异常即所填写的内容是“throws EmptyQueueException”。
(4)空缺处可以使用throw语句抛出异常而使用throw语句时需要一个参数即一个可抛出的对象因此(4)空缺处所填写的内容是“throw(new EmptyQueueException())”。
try块和catch块是异常处理器的两个组件。在try块中产生的异常通常被紧跟其后的catch块指定的处理器捕获。
try {
可能抛出异常的语句
}
catch(异常类型 异常引用) {
处理异常的语句
}
catch语句可以有多个分别处理不同类的例外。Java运行时系统从上到下分别对每个catch语句处理的例外类型进行检测直到找到类型相匹配的catch语句为止。其中类型匹配是指catch所处理的例外类型与生成的例外对象的类型完全一致或者是它的父类因此catch语句的排列顺序应该是从特殊到一般。也可以用一个catch语句处理多个例外类型此时它的例外类型参数应该是这几个例外类型的父类程序设计中要根据具体的情况来选择catch语句的例外处理类型。
在选择要抛出的异常的类型时可以使用其他人编写的异常类也可以编写自己的异常类。本试题中采用自定义的类作为异常的类型。
仔细阅读试题中给出的Java源代码可知主类TestMain包含了异常处理机制用于检测在出队时“队列为空”的错误。因此(1)空缺处所填写的内容是“try”。
由catch语句的语法可知(2)空缺处所填写的内容是对相应异常类型的引用。结合试题中给出的关键信息“类EmptyQueueException给出了队列操作中的异常处理操作”即类EmptyQueueException是进行异常处理的类因此(2)空缺处所填写的内容是“EmptyQueueExceptione”或者“Exceptione”其中e是对象名可用任意合法标识符替换。
由于异常都是从超类Exception派生而来的因此(5)空缺处所填写的内容是“Exception”。
仔细阅读主类TestMain程序段可以看到在try块的内部并没有给出显示的抛出异常语句即没有出现throw语句。结合(4)空缺处所在行的注释—“队列为空抛出异常”可以推断在类Queue的方法dequeue中必定要抛出异常。因此(3)空缺处应指定方法dequeue可以抛出异常即所填写的内容是“throws EmptyQueueException”。
(4)空缺处可以使用throw语句抛出异常而使用throw语句时需要一个参数即一个可抛出的对象因此(4)空缺处所填写的内容是“throw(new EmptyQueueException())”。这是一道要求读者掌握Java异常处理机制的程序分析题。本题的解答思路如下。 异常是指计算机程序执行期间中断的正常流程的事件。例外是在程序运行过程中发生的异常事件,比如除0溢出、数组越界、文件找不到等,这些事件的发生将阻止程序的正常运行。 当一个方法中发生错误时,该方法创建一个对象(该对象称之为异常对象)并将它交给运行时系统。异常对象包含了关于错误的信息,即包括错误的类型和错误发生时程序的状态。 “抛出一个异常”是指创建异常对象并将它交给运行时系统。Java的异常处理是通过try、catch、throw、 throws和finally 5个关键字来实现的。这几个关键字的解释如表4-15所示。
Java运行时系统要求方法必须捕获或者指定它可以抛出的所有被检查的异常,如表4-16所示。
try块和catch块是异常处理器的两个组件。在try块中产生的异常通常被紧跟其后的catch块指定的处理器捕获。
try {
可能抛出异常的语句
}
catch(异常类型 异常引用) {
处理异常的语句
}
catch语句可以有多个,分别处理不同类的例外。Java运行时系统从上到下分别对每个catch语句处理的例外类型进行检测,直到找到类型相匹配的catch语句为止。其中,类型匹配是指catch所处理的例外类型与生成的例外对象的类型完全一致或者是它的父类,因此,catch语句的排列顺序应该是从特殊到一般。也可以用一个catch语句处理多个例外类型,此时它的例外类型参数应该是这几个例外类型的父类,程序设计中要根据具体的情况来选择catch语句的例外处理类型。
在选择要抛出的异常的类型时,可以使用其他人编写的异常类,也可以编写自己的异常类。本试题中采用自定义的类作为异常的类型。
仔细阅读试题中给出的Java源代码可知,主类TestMain包含了异常处理机制,用于检测在出队时“队列为空”的错误。因此(1)空缺处所填写的内容是“try”。
由catch语句的语法可知,(2)空缺处所填写的内容是对相应异常类型的引用。结合试题中给出的关键信息“类EmptyQueueException给出了队列操作中的异常处理操作”,即类EmptyQueueException是进行异常处理的类,因此(2)空缺处所填写的内容是“EmptyQueueExceptione”,或者“Exceptione”,其中,e是对象名,可用任意合法标识符替换。
由于异常都是从超类Exception派生而来的,因此(5)空缺处所填写的内容是“Exception”。
仔细阅读主类TestMain程序段可以看到,在try块的内部并没有给出显示的抛出异常语句,即没有出现throw语句。结合(4)空缺处所在行的注释—“队列为空,抛出异常”可以推断,在类Queue的方法dequeue中必定要抛出异常。因此(3)空缺处应指定方法dequeue可以抛出异常,即所填写的内容是“throws EmptyQueueException”。
(4)空缺处可以使用throw语句抛出异常,而使用throw语句时需要一个参数,即一个可抛出的对象,因此(4)空缺处所填写的内容是“throw(new EmptyQueueException())”。
第6题:
A.Document,Node
B.Node,NodeList
C.NodeList,Element
D.Node,Element
第7题:
阅读下列函数说明和Java代码,将应填入(n)处的字句写在对应栏内。
【说明】
类Queue表示队列,类中的方法如下表所示。

类Node表示队列中的元素;类EmptyQueueException给出了队列操作中的异常处理操作。
public class TestMain { //主类
public static viod main (String args[]){
Queue q=new Queue();
q.enqueue("first!");
q.enqueue("second!");
q.enqueue("third!");
(1) {
while(true)
System.out.println(q.dequeue());
}
catch( (2) ){ }
}
public class Queue { //队列
Node m_FirstNode;
public Queue(){m_FirstNode=null;}
public boolean isEmpty(){
if(m_FirstNode==null)return true;
else return false;
}
public viod enqueue(Object newNode) { //入队操作
Node next=m_FirstNode;
if(next==null)m_FirstNode=new Node(newNode);
else{
while(next.getNext()!=null)next=next.getNext();
next.setNext(new node(newNode));
}
}
public Object dequeue() (3) { //出队操作
Object node;
if (isEempty())
(4); //队列为空, 抛出异常
else{
node=m_FirstNode.getObject();
m_FirstNode=m_FirstNode.getNext();
return node;
}
}
}
public class Node{ //队列中的元素
Object m_Data;
Node m_Next;
public Node(Object data) {m_Data=data; m_Next=null;}
public Node(Object data, Node next) {m_Data=data; m_Next=-next;}
public void setObject(Object data) {m_Data=data;}
public Object getObject(Object data) {return m_data;}
public void setNext(Node next) {m_Next=next;}
public Node getNext() {return m_Next;}
}
public class EmptyQueueException extends (5) { //异常处理类
public EmptyQueueException() {
System.out.println("队列已空! ");
}
}
(1)try (2)Exception e或者EmptyQueueException e (3)throw EmptyQueueException (4)throw(new EmptyQueueException()) (5)Exception 解析:(1)try
从紧随其后的catch可以断定这是异常处理的try-catch结构。
(2)Exception e或者EmptyQueueException e
其中e是对象名,可用任意合法标识符替换,这是catch要捕获的信息。
(3)throw EmptyQueueException
当队列为空时,抛出错误信息EmptyQueueException。
(4)throw(new EmptyQueueException())
当队列为空时,抛出异常。动态生成EmptyQueueException对象,出错处理。
(5)Exception
EmptyQueueException对象是从异常处理类Exception扩展而来。
第8题:
A.SAX是比DOM更快、更轻量级的处理XML文档的方法
B.XSLT除了可以定制XML文档在浏览器中的显示外,还可以将一个XML文档转换成另一种数据结构的XML文档
C.一个良构(Well-FormeD.的XML文档必定也是符合DTD或XMLSchema语义验证的
D.XML文档中可以自定义标签,而HTML中则不行
第9题:
在C语言中,可以用typedef声明新的类型名来代替已有的类型名,比如有学生链表结点: typedef struct node{ int data; struct node * link; }NODE, * LinkList; 下述说法正确的是______。
A.NODE是结构体struct node的别名
B.* LinkList也是结构体struct node的别名
C.LinkList也是结构体struct node的别名
D.LinkList等价于node*
解析:其实题中的定义相当于下述两个定义:typedefstructnode{intdata;structnode*link;}NODE;typedefstructnode{intdata;structnode*link;)*LinkList;前者给structnode取了个新名字NODE,即structnode和NODE是等价的;后者把structnode*命名为LinkList。
第10题:
[说明]
已知包含头节点(不存储元素)的单链表的元素已经按照非递减方式排序,函数compress(NODE *head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。
处理过程中,当元素重复出现时,保留元素第一次出现所在的节点。
图8-29(a)、(b)是经函数compress( )处理前后的链表结构示例图。

链表的节点类型定义如下:
typedef struct Node {
int data;
struct Node *next;
}NODE;
[C语言函数]
void compress(NODE *head)
{
NODE *ptr, *q;
ptr= (1) ; /*取得第一个元素节点的指针*/
while( (2) && ptr->next) {
q=ptr ->next;
while(q && (3) ){/*处理重复元素*/
(4) =q ->next;
free(q);
q=ptr->next;
}
(5) =ptr->next;
} /*end of while*/
} /*end of compress*/
head>next ptr ptr->data==q->data或其等价形式 ptr->next ptr 解析:本题考查的是对链表的查找、插入和删除等运算。要找到重复的元素并将其删除而使各元素互不相同。我们可以顺序遍历链表,比较逻辑上相邻的两个元素是否相同,如果相同则删除后一个元素,以此类推。代码如下:
VOid Compress(NODE *head)
{
NODE *ptr, *q;
ptr=head->next; /*取得第一个元素节点的指针*/
while(ptr && ptr->next){
q=ptr->next;
while(q && ptr->data==q>data){/*处理重复元素*/
ptr->next=q->next;
free(q);
q=ptr->next;
}
ptr=ptr->next;
}/*end of while*/
}/*end of compress*/