
sokaoti.com
中国长城计算机深圳股份有限公司11月招聘面试题111道20201126
●试题三
阅读下列说明和C代码,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
本题给出四个函数,它们的功能分别是:
1.int push(PNODE *top,int e)是进栈函数,形参top是栈顶指针的指针,形参e是入栈元素。
2.int pop(PNODE *top,int *e)是出栈函数,形参top是栈顶指针的指针,形参e作为返回出栈元素使用。
3.int enQueue(PNODE *tail,int e)是入队函数,形参tail是队尾指针的指针,形参e是入队元素。
4.int deQueue(PNODE *tail,int *e)是出队函数,形参tail是队尾指针的指针,形参e作为返回出队元素使用。
以上四个函数中,返回值为0表示操作成功,返回值为-1表示操作失败。
栈是用链表实现的;队是用带有辅助结点(头结点)的单向循环链表实现的。两种链表的结点类型均为:
typedef struct node{
int value;
struct node *next;
}NODE,*PNODE;
【函数1】
int push(PNODE *top,int e)
{
PNODE p=(PNODE)malloc (sizeof(NODE));
if (!p) return-1;
p-> value =e;
(1) ;.
*top=p;
return 0;
}
【函数2】
int pop (PNODE *top,int *e)
{
PNODE p=*top;
if(p==NULL)return-1;
*e=p->value;
(2) ;
free(p);
return 0;
}
【函数3】
int enQueue (PNODE *tail,int e)
{PNODE p,t;
t=*tail;
p=(PNODE)malloc(sizeof(NODE));
if(!p)return-l;
p->value=e;
p->next=t->next;
(3) ;
*tail=p;
return 0;
}
【函数4】
int deQueue(PNODE *tail,int *e)
{PNODE p,q;
if((*tail)->next==*tail)return -1;
p=(*tail)->next;
q=p->next;
*e=q->value;
(4) =q->next;
if(*tail==q) (5) ;
free(q);
return 0;
}
●试题三
【答案】(1)p->next=*top(2)*top=p->next或*top=(*top)->next
(3)t->next=p或(*tail)->next=p(4)p->next或(*tail)->next->next
(5)*tail=p或*tail=(*tail)->next
【解析】(1)插入结点p后,p应当指向插入前头结点,所以填入p->next=*top。(2)出栈后,头指针应指向它的下一结点,所以填入*top=p->next或*top=(*top)->next。(3)入队时,需要将结点插入队尾,所以应当填入(*tail)->next=p或t->next=p(t也指向尾结点)。(4)出队时,需要删除队头结点,通过(*tail)->next可以得到对队头结点的引用。(4)处是正常删除队头结点的情况,空格处应填入头结点指向下一结点的指针,即p->next或(*tail)->next->next。(5)处是需要考虑的特殊情况,即队列中最后一个元素出队后,要更新队尾指针,即填入*tail=p或*tail=(*tail)->next。
下列的说法中,不正确的是()
A.迭代器协议是指:对象必须提供一个next方法
B.list、dict、str虽然是Iterable,却不是Iterator
C.生成器与迭代器对象的区别在于:它仅提供next()方法
D.生成器实现了迭代器协议,但生成器是边计算边生成达到节省内存及计算资源
Python内置函数__________可以返回列表、元组、字典、集合、字符串以及range对象中元素个数。
Python内置函数__________用来返回序列中的最小元素。
Python内置函数_____________用来打开或创建文件并返回文件对象。
中国长城计算机深圳股份有限公司11月招聘面试题面试题面试官常问到的一些题目整理如下:问题 Q1:迭代器和生成器的区别?可用的回答 : 1)迭代器是一个更抽象的概念,任何对象,如果它的类有next方法和iter方法返回自己本身。对于 string、list、dict、tuple等这类容器对象,使用for循环遍历是很方便的。在后台for语句对容器对象调 用iter()函数,iter()是python的内置函数。iter()会返回一个定义了next()方法的迭代器对象,它在容器中 逐个访问容器内元素,next()也是python的内置函数。在没有后续元素时,next()会抛出一个 StopIteration异常 2)生成器(Generator)是创建迭代器的简单而强大的工具。它们写起来就像是正规的函数,只是在需 要返回数据的时候使用yield语句。每次next()被调用时,生成器会返回它脱离的位置(它记忆语句最后 一次执行的位置和所有的数据值) 区别:生成器能做到迭代器能做的所有事,而且因为自动创建了iter()和next()方法,生成器显得特别简洁, 而且生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保存程序状态 的自动方法,当发生器终结时,还会自动抛出StopIteration异常 问题 Q2:用尽量多的方法实现单例模式?可用的回答 : 一、模块单例 Python 的模块就是天然的单例模式,因为模块在第一次导入时,会生成.pyc文件,当第二次导入时,就会直接加载.pyc文件,而不会再次执行模块代码。 二、静态变量方法 先执行了类的_new_方法(我们没写时,默认调用object._new_),实例化对象; 然后再执行类的_init_方法,对这个对象进行初始化,所有我们可以基于这个,实现单例模式。 class Singleton(object): def _new_(cls,a): if not hasattr(cls, _instance): cls._instance = object._new_(cls) return cls._instance def _init_(self,a): self.a = a 问题 Q3:如何将数字转换为字符串?可用的回答 :要将数字转换为字符串,请使用内置函数str()。如果需要八进制或十六进制表示,请使用内置函数oct()或hex()问题 Q4:如何在Python中删除文件?可用的回答 :使用命令os.remove(filename) 删除文件 或 os.unlink(filename) 删除快捷方式问题 Q5:描述一下scrapy框架的运行机制?可用的回答 : 从start_urls里面获取第一批url发送请求,请求由请求引擎给调度器入请求对列,获取完毕后, 调度器将请求对列交给下载器去获取请求对应的响应资源,并将响应交给自己编写的解析方法做提取处理,如 果提取出需要的数据,则交给管道处理,如果提取出url,则继续执行之前的步骤,直到多列里没有请求,程序结束。 问题 Q6:列举面向对象中带双下划线的魔术方法可用的回答 : _doc_ 表示类的描述信息 _module_ 表示当前操作的对象在哪个模块 _class_ 表示当前操作的对象的类是什么 _init_ 构造方法,通过类创建对象时,自动触发执行 _new_负责创建一个类的对象 _del_ 析构方法,当对象在内存中被释放时,自动触发执行 _call_ 对象后面加括号,触发执行 _dict_ 类或对象中的所有成员 _str_如果一个类中定义了_str_方法,那么在打印 对象 时,默认输出该方法的返回 问题 Q7:参数如何通过值或引用传递?可用的回答 :Python中的所有内容都是一个对象,所有变量都包含对象的引用问题 Q8:如何在Python中复制对象?可用的回答 :要在Python中复制对象,可以尝试copy.copy() 或 copy.deepcopy() 来处理一般情况。copy.copy()浅拷贝,复制引用;copy.deepcopy()深拷贝,完全独立的对象问题 Q9:大数据的文件读取?可用的回答 : 1. 利用生成器generator 2. 迭代器进行迭代遍历:for line in file 问题 Q10:描述数组、链表、队列、堆栈的区别?可用的回答 : 数组与链表是数据存储方式的概念,数组在连续的空间中存储数据,而链表可以在非连续的空间中存储数据; 队列和堆栈是描述数据存取方式的概念,队列是先进先出,而堆栈是后进先出; 队列和堆栈可以用数组来实现,也可以用链表实现。 算法题面试官常问到的一些算法题目整理如下(大概率会机考):算题题 A1:独一无二的邮箱地址题目描述如下:Every email consists of a local name and a domain name, separated by the sign.For example, in , alice is the local name, and is the domain name.Besides lowercase letters, these emails may contain .s or +s.If you add periods (.) between some characters in the local name part of an email address, mail sent there will be forwarded to the same address without dots in the local name. For example, and forward to the same email address. (Note that this rule does not apply for domain names.)If you add a plus (+) in the local name, everything after the first plus sign will be
此题为判断题(对,错)。
阅读下列说明和C代码,将应填入(n)处的字句写在对应栏内。
【说明】
本题给出四个函数,它们的功能分别是:
1.int push(PNODE*top,int e)是进栈函数,形参top是栈顶指针的指针,形参e是入栈元素。
2.int pop(PNODE*top,int*e)是出栈函数,形参top是栈顶指针的指针,形参e作为返回出栈元素使用。
3.int enQueue(PNODE*tail,int e)是入队函数,形参tail是队尾指针的指针,形参e是入队元素。
4.int deQueue(PNODE*tail,int*e)是出队函数,形参tail是队尾指针的指针,形参e作为返回出队元素使用。
以上四个函数中,返回值为。表示操作成功,返回值为-1表示操作失败。
栈是用链表实现的;队是用带有辅助结点(头结点)的单向循环链表实现的。两种链表的结点类型均为:
typedef struct node {
int value;
struct node * next;
} NODE, * PNODE;
【函数1】
int push(PNOOE * top,int e)
{
PNODE p = (PNODE) malloc (sizeof (NODE));
if (! p) return-1;
p->value=e;
(1);
*top=p;
return 0;
}
【函数2】
int pop (PNODE * top,int * e)
{
PNODE p = * top;
if(p == NULL) return-1;
* e = p->value;
(2);
free(p);
return 0;
}
【函数3】
int enQueue (PNODE * tail,int e)
{ PNODE p,t;
t= *tail;
p = (PNODE) malloc(sizeof(NODE));
if(!p) return-1;
p->value=e;
p->next=t->next;
(3);
* tail = p;
return 0;
}
【函数4】
int deQueue(PNODE * tail,int * e)
{ PNODE p,q;
if(( * tail)->next == * tail) return-1;
p= (* tail)->next;
q = p ->next;
* e =q ->value;
(4)=q->next;
if(,tail==q) (5);
free(q);
return 0;
}
(1)p->next=*top (2)*top=p->next或* top=(*top)->next (3)t->next=p或(*tail)->next=p (4)p->next或(*tail)->next->next (5)*tail=p或*tail=(*tail)->next 解析:(1)插入结点p后,p应当指向插入前头结点,所以填入p ->next=*top。(2)出栈后,头指针应指向它的下一结点,所以填入 *top=p->next或*top=(*top)->next。(3)入队时,需要将结点插入队尾,所以应当填入(*tail)->next=p或t->next=p(t也指向尾结点)。(4)出队时,需要删除队头结点,通过(*tail)->next可以得到对队头结点的引用。(4)处是正常删除队头结点的情况,空格处应填入头结点指向下一结点的指针,即p->next或(*tail)->next->next。(5)处是需要考虑的特殊情况,即队列中最后一个元素出队后,要更新队尾指针,即填入*tail=p或*tail=(*tail)->next。
阅读以下说明和C语言函数,将应填入(n)。
【说明】
已知包含头结点(不存储元素)的单链表的元素已经按照非递减方式排序,函数 compress(NODE*head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。
处理过程中,当元素重复出现时,保留元素第一次出现所在的结点。
图2-1(a)、(b)是经函数compress()处理前后的链表结构示例图。
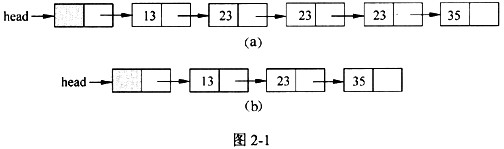
链表的结点类型定义如下:
typedef struct Node{
int data;
struct Node *next;
}NODE;
【C语言函数】
void compress(NODE *head)
{ NODE *ptr,*q;
ptr= (1); /*取得第一个元素结点的指针*/
while( (2)&& ptr->next) {
q=ptr->next;
while(q&&(3)) { /*处理重复元素*/
(4)q->next;
free(q);
q=ptr->next;
}
(5) ptr->next;
}/*end of while */
}/*end of compress*/
(1)head->next (2)ptr (3)q->data == ptr->data 或ptr->next->data==ptr->data,或其等价表示 (4)ptr->next (5)ptr 解析:本题考查基本程序设计能力。
链表上的查找、插入和删除运算是常见的考点。本题要求去掉链表中的重复元素,使得链表中的元素互不相同,显然是对链表进行查找和删除操作。
对于元素已经按照非递减方式排序的单链表,删除其中重复的元素,可以采用两种思路。
1.顺序地遍历链表,对于逻辑上相邻的两个元素,比较它们是否相同,若相同,则删除后一个元素的结点,直到表尾。代码如下:
ptr=head->next;/*取得第一个元素结点的指针*/
while(ptr && ptr->next){ /*指针ptr指示出重复序列的第一个元素结点*/
q=ptr->next;
while(q && ptr->data==q->data){/*处理重复元素*/
ptr->next=q->next;/*将结点从链表中删除*/
free(q);
q=ptr->next; /*继续扫描后继元素*/
}
ptr=ptr->next;
}
2.对于每一组重复元素,先找到其中的第一个结点,然后向后查找,直到出现一个相异元素时为止,此时保留重复元素的第一个结点,其余结点则从链表中删除。
ptr=head->next;/*取得第一个元素结点的指针*/
while(ptr && ptr->next){/*指针ptr指示出重复序列的第一个元素结点*/
q=ptr->next;
while(q && ptr->data==q->data) /*查找重复元素*/
q=q->next;
s=ptr->next; /*需要删除的第一个结点*/
ptr->next=q; /*保留重复序列的第一个结点,将其余结点从链表中删除*/
while(s && s!=q}{/*逐个释放被删除结点的空间*/
t = s->next;free(s);s = t;
}
ptr=ptr->next;
}
题目中采用的是第一种思路。
使用Function语句定义一个函数过程时,其返回值的类型( )。【考点2创建模块】
A.只能是符号常量
B.是除数组之外的简单数据类型
C.可在调用时由运行过程决定
D.由函数定义时As子句声明
暂无解析,请参考用户分享笔记
[说明]
已知包含头节点(不存储元素)的单链表的元素已经按照非递减方式排序,函数compress(NODE *head)的功能是去掉其中重复的元素,使得链表中的元素互不相同。
处理过程中,当元素重复出现时,保留元素第一次出现所在的节点。
图8-29(a)、(b)是经函数compress( )处理前后的链表结构示例图。

链表的节点类型定义如下:
typedef struct Node {
int data;
struct Node *next;
}NODE;
[C语言函数]
void compress(NODE *head)
{
NODE *ptr, *q;
ptr= (1) ; /*取得第一个元素节点的指针*/
while( (2) && ptr->next) {
q=ptr ->next;
while(q && (3) ){/*处理重复元素*/
(4) =q ->next;
free(q);
q=ptr->next;
}
(5) =ptr->next;
} /*end of while*/
} /*end of compress*/
head>next ptr ptr->data==q->data或其等价形式 ptr->next ptr 解析:本题考查的是对链表的查找、插入和删除等运算。要找到重复的元素并将其删除而使各元素互不相同。我们可以顺序遍历链表,比较逻辑上相邻的两个元素是否相同,如果相同则删除后一个元素,以此类推。代码如下:
VOid Compress(NODE *head)
{
NODE *ptr, *q;
ptr=head->next; /*取得第一个元素节点的指针*/
while(ptr && ptr->next){
q=ptr->next;
while(q && ptr->data==q>data){/*处理重复元素*/
ptr->next=q->next;
free(q);
q=ptr->next;
}
ptr=ptr->next;
}/*end of while*/
}/*end of compress*/