
软考初级
试题一(共15 分 )阅读以下说明和流程图,将应填入 (n) 处的字句写在答题纸的对应栏内。【 说明 】下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在“aaaa”中只出现两次“aa”。该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i 为字符串 A 中当前正在进行比较的动态子
题目
试题一(共15 分 )
阅读以下说明和流程图,将应填入 (n) 处的字句写在答题纸的对应栏内。
【 说明 】
下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。
设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在“aaaa”中只出现两次“aa”。
该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i 为字符串 A 中当前正在进行比较的动态子串首字符的下标,j为字符串B 的下标,k为指定关键词出现的次数。
相似问题和答案
第1题:
阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入对应栏内。
【说明】
下面流程图的功能是:在已知字符串A中查找特定字符串B,如果存在,则输出B串首字符在A串中的位置,否则输出-1。设串A由n个字符A(0),A(1),…,A(n-1)组成,串B由m个字符B(0),B(1),…,B(m-1)组成,其中n≥m>0。在串A中查找串 B的基本算法如下:从串A的首字符A(0)开始,取子串A(0)A(1)…A(m-1)与串B比较;若不同,则再取子串A(1)A(2)…A(m)与串B比较,依次类推。
例如,字符串“CABBRFFD”中存在字符子串“BRF”(输出3),不存在字符子串“RFD”(输出-1)。
在流程图中,i用于访问串A中的字符(i=0,1,…,n-1),j用于访问串B中的字符(j=0,1,…,m-1)。在比较A(i)A(i/1)…A(i+m-1)与B(0)B(1)…B(m-1)时,需要对 A(i)与B(0)、A(i+1)与B(1)、…、A(i+j)与B(j)等逐对字符进行比较。若发现不同,则需要取下一个子串进行比较,依此类推。
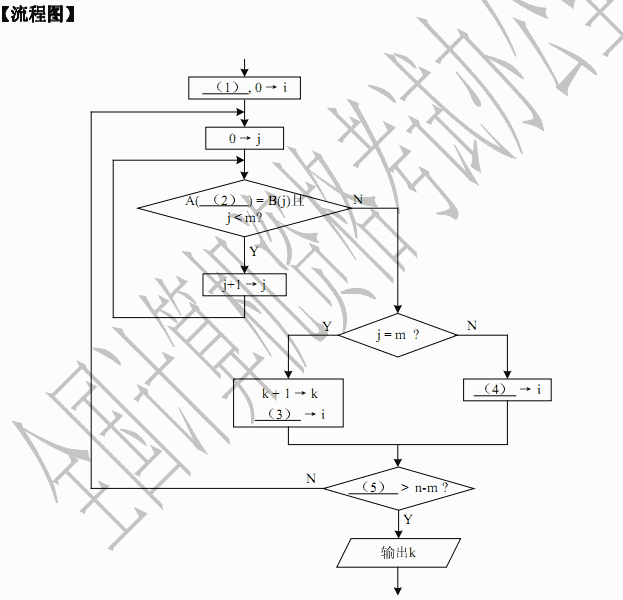
【流程图】

(1) j+1 (2) i+1 (3) 0 (4) i (5) -1 解析:本题采用的是最简单的字符子串查找算法。
在串A中查找是否含有串B,通常是在串A中从左到右取逐个子串与串B进行比较。在比较子串时,需要从左到右逐个字符进行比较。
题中已设串A的长度为n,存储数组为A,动态指针标记为i;串B的长度为m,存储数组为B,动态指针标记为j。
如果用伪代码来描述这种算法的核心思想,则可以用以下的两重循环来说明。
外循环为:
Fori=0ton-mdo
A(i)A(i+1)...A(i+m-1)~B(0)B(1)...B(m-1)
要实现上述比较,可以采用内循环:
Forj=0tom-1do
A(i+j)~B(j)
将这两重循环合并在一起就是:
Fori = 0ton-1do
Forj = 0tom-1do
A(i+j)~B(j)
这两重循环都有一个特点:若发现比较的结果不相同时,就立即退出循环。因此,本题中的流程图可以间接使用循环概念。
初始时,i与j都赋值0,做比较A(i+j)~B(j)。
若发现相等,则继续内循环(走图的左侧),j应该增1,继续比较,直到j=m为止,表示找到了子串(应输出子串的起始位置i);若发现不等,则退出内循环,继续开始外循环(走图的右侧),j应恢复为0,i应增1,继续比较,直到i>n-m为止,表示不存在这样的子串(输出-1)。
在设计流程图时,主要的难点是确定循环的边界(何时开始,何时结束)。当难以确定边界值变量的正确性时,可以用具体的数值之例来验证。这是程序员应具备的基本素质。
第2题:
阅读下列说明和流程图,将应填入(n)的字句写在对应栏内。
【说明】
下列流程图(如图4所示)用泰勒(Taylor)展开式
sinx=x-x3/3!+x5/5!-x7/7!+…+(-1)n×x2n+1/(2n+1)!+…
【流程图】
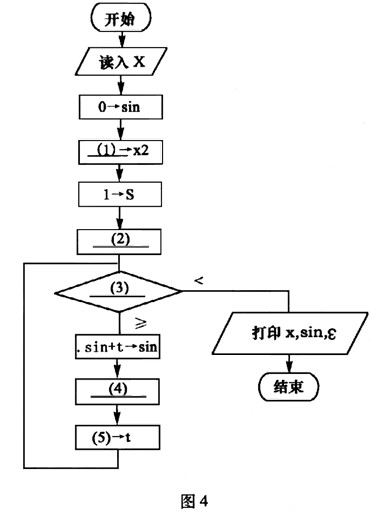
计算并打印sinx的近似值。其中用ε(>0)表示误差要求。
(1)x*x (2)x->t (3)│t│:ε (4)s+2->s (5)(-1) * t* x2/(s* (s-1)) 解析:该题的关键是搞清楚几个变量的含义。很显然变量t是用来保存多项式各项的值,变量s和变量x2的作用是什么呢?从流程图的功能上看,需要计算11、3!、5!,……,又从变量s的初值置为1可知,变量s主要用来计算这此数的阶乘的,但没有其他变量用于整数自增,这样就以判断s用来存储奇数的,即s值依次为1、3、5,……。但x2的功能还不明确,现在可以不用管它。
(2)空的作用是给t赋初值,即给它多项式的第一项,因此应填写“x->t”。(3)空处需填写循环条件,显然当t的绝对值小于ε(>0)就表示已经达到误差要求,因此(3)空应填入“│t│:ε”。由变量s的功能可知,(4)空应当实现变量s的增加,因此(4)空应填入“s+2->s”。 (5)空应当是求多项式下一项的值,根据多项式连续两项的关系可知,当前一项为t时,后一项的值为(-1)*t*x*x/(s*(s-1))。但这样的话,每次循环都需要计算一次x*x,计算效率受到影响,联想到变量x2还没用,这时就可以判断x2就是用来存储x*x的值,使得每次循环者少进行一次乘法运算。因此(1)空处应填入“x*x”,(5)空处应填入“(-1)*t*x2/(s*(s-1))”。
第3题:
阅读下列说明和流程图,将应填入(n)处的语句写在对应栏内。
【说明】
下列流程图用于从数组K中找出一切满足:K(I)+K(J)=M的元素对(K(I),K(J))(1≤I≤J≤N)。假定数组K中的N个不同的整数已按从小到大的顺序排列,M是给定的常数。
【流程图】
此流程图1中,比较“K(I)+K(J):M”最少执行次数约为(5)。
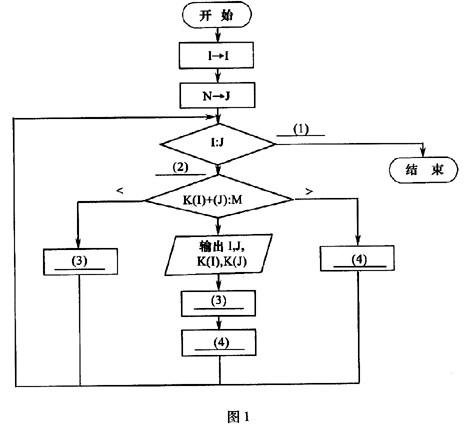
(1) (2) (3)I+1->I (4)J-1->J (5)[N/2] 解析:该算法的思路是:设置了两个变量I和J,初始时分别指向数组K的第一个元素和最后一个元素。如果这两个元素之和等于M时,输出结果,并这两个指针都向中间移动;如果小于M,则将指针I向中间移动(因为数组K已按从小到大的顺序排列);如果大于M,则将指针J向中间移动(因为数组K已按从小到大的顺序排列)。当IJ时,说明所有的元素都搜索完毕,退出循环。
根据上面的分析,(1)、(2)空要求填写循环结束条件,显然,(1)空处应填写“”,(2)空处应填写“”。这里主要要注意I=J的情况,当I=J时,说明指两个指针指向同一元素,应当退出循环。
(3)空在流程图有两处,一处是当K(I)+K(J)=M时,另一处是当K(I)+K(J)M时,根据上面分析这两种情况都要将指针I向中间移动,即“I+1->I”。同样的道理,(4)空处应填写“J-1->J”。
比较“K(I)+K(J):M”最少执行次数发生在第1元素与第N个元素之和等于M、第2元素与第N-1个元素之和等于M、……,这样每次比较,两种指针都向中间移动,因此最小执行次数约为“N-2”。
第4题:
阅读以下说明和流程图,将应填入(n)处的字句写在对应栏内。
[说明]
下面的流程图实现了正整数序列{K(1),K(2),…,K(n)}的重排,得到的新序列中,比K(1)小的数都在K(1)的左侧,比K(1)大的数都在K(1)的右侧。以n=6为例,序列{12,2,9,13,21,8}的重排过程为:
{12,2,9,13,21,8}
→{2,12,9,13,21,8}
→{9,2,12,13,21,8}
→{8,9,2,12,13,21}
[流程图]
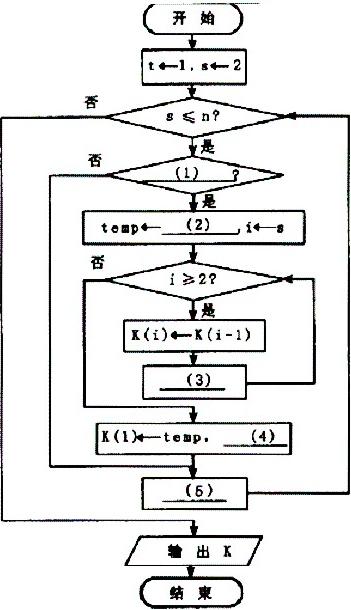
(1) K(s)K(t) (2) K(s) (3) i←i-1 (4) t←t+1 (5) s←s+1 解析:算法中变量K(t)始终代表原始序列中的K(1)值,t则代表它在当前序列中的位置编号,初始值为1; k(s)代表待比较的数。算法首先拿K(t)和其后的数做比较,若K(s)比K(t)小,则K(s)移至序列的最左侧,同时顺次把第i,is位的元素向右移一位。让s自增1,重复这一步骤,直至到达序列末端(即s=n)为止。
第5题:
阅读下列说明和流程图,将应填入(n)处的语句写在对应栏内。
【说明】
下列流程图用泰勒(Taylor)展开式y=ex=1+x+x2/2!+x3/3!+…+xn/n!+…计算并打印ex的近似值,其中用ε(>0)表示误差要求。
【流程图】
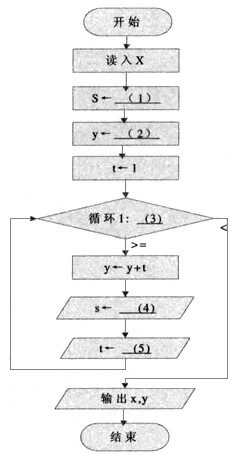
(1)0 (2)0 (3)|t|:ε (4)s+1 (5)t*x/s 解析:本题考查程序流程图的内容。
首先让我们来了解一下题目的真正含义,题目要求用泰勒展开式计算y=ex的近似值。并且给出了误差要求,只要当误差小于ε时,就可以输出计算结果了。泰勒展开式的式子是n项之和,每多加一项,其值就越接近真实值。因此,在程序设计时,每加一项之前,先进行此项与ε的比较,来判定计算结果是否已满足题目要求。
从流程图中看到有S、y、t、x这几个变量。其中x、y是公式中的变量,而S、t则是中间变量。从y←y+t语句可以看出,t是每次要加的项,S则是帮助t改变的变量。在计算开始前,我们应该将y的值赋为零,因此,第(2)空答案就为0;而S在t没发生变化的初值也应该是0,即第(1)空答案为0。
第(3)空处是个条件判断语句,应该是进行该加项与ε比较判断,因此第(3)空的答案是|t|:ε。
第(4)空与第(5)空要一起考虑。由于S是帮助t改变的变量,而t的每次改变是分母乘以一个加1的数,而分子乘以x。这里假设S是帮助t改变分母的变量,第(4)空应填s+1,那么第(5)空应该为t*x/s。
第6题:
阅读以下说明和流程图,将应填入(n)处的字句写在对应栏内。
[说明]
设学生某次考试的成绩按学号顺序逐行存放于某文件中,文件以单行句点“.”为结束符。下面的流程图读取该文件,统计出全部成绩中的最高分max和最低分min。

(1) max←a (2) min←a (3) a="." (4) a>max或amax或maxa或max≤a (5) amin或a≤min或min>a或mina 解析:本题用到的三个变量及其作用分别为:a,存放读入的一行数据;max存放最高分;min存放最低分。算法首先读入文件的第一行数据a,若a为文件结束符“.”,则算法提前结束;否则为max和min赋初值a,循环读入文件其余部分,直至文件末尾。循环过程中,当某行数据a大于max时,更新max的值;当某行数据a小于min时,更新min的值。
第7题:
阅读以下说明和流程图,填补流程图中的空缺(1)一(5),将解答填入答题纸的对应栏内。
【说明】
下面的流程图采用公式ex=1+x+x2/2 1+x3/3 1+x4/4 1+…+xn/n!+???计算ex的近似值。设x位于区间(0,1),该流程图的算法要点是逐步累积计算每项xx/n!的值(作为T),再逐步累加T值得到所需的结果s。当T值小于10-5时,结束计算。
【流程图】
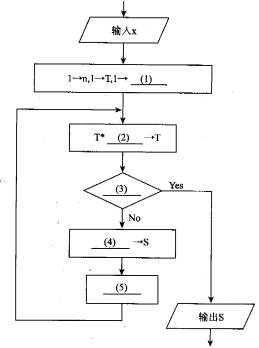
(1)S (2)x/n (3)T<O.00001 (4)S+T (5)n+1->n 解析:在题目中已经给出了指数函数ex的公式,即基本算法,另外也给出了计算过程中控制误差终止计算的方法。本题主要的重点是如何设计计算流程,实现级数前若干项的求和,以及判断计算终止的条件。级数求和一般都是采用逐项累加的方法。从流程图我们可以看出s为累加结果,T为动态的项值,最后通过s+T->S来完成各项的累加。已知T=xnx/n!,如果每次都直接计算T的值,计算量会比较大。从ex的公式中我们可以看出每一项都一个共同点,就是后一项和前一项有简单的关系Tn=T(n-i)*x/n,我们可以充分利用前项的计算结果来计算后一项,这样就会大大减少计算量。这也是程序员需要掌握的基本技巧。在流程图中,一开始先输入变量x,接着对其他变量赋初值。级数项号n的初始值为1,逐次进行累积的T的初始值为1,根据后面的流程推断可以看出逐次进行累加的s应该有初始值l的(在输入的x满足条件直接退出循环的时候根据公式输出的值为D,所以空(1)的答案为“S”。从前面分析直到e。的公式中后一项和前一项有简单的关系Tn=T(n-i)*x/n,所以空(2)的答案为“x/n”。空(3)处是判断计算过程结束的条件,按照题目中的要求“当T值小于lO-5时,结束计算。”所以空(3)的答案为“T<0.00001”。按照题意空(4)处是要对每项的结果进行累加赋给S,实现s+T->s,所以空(4)的答案为“S+T”。流程走到空(5)的时候已经求出第n项的值Tn,并累加到s中,根据算法下一步应该计算第n+1项的值,所以这里需要对级数的项号n进行自增,空(5)的答案可以为“n+=1”或者n++,但是根据流程图以上的书写风格写为“n+1->n”应该是最佳答案。
第8题:
阅读以下说明和流程图,将应填入(n)处的字句写在对应栏内。
【说明】
已知头指针分别为La和lb的有序单链表,其数据元素都是按值非递减排列。现要归并La和Lb得到单链表Lc,使得Lc中的元素按值非递减排列。程序流程图如下所示:
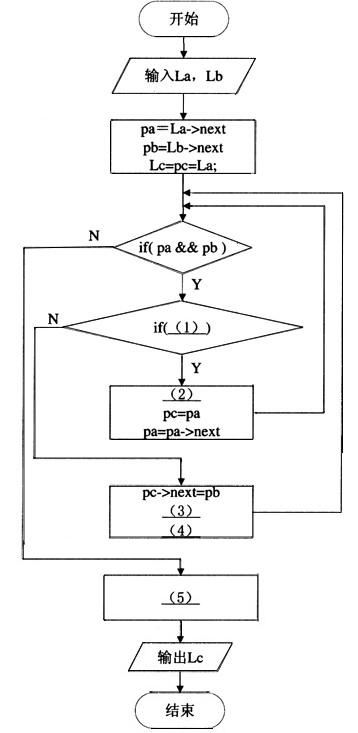
(1)pa->data=pb->data (2)pc->next=pa (3)pc=pb (4)pb=pb->next (5)pc->next=pa?pa:pb 解析:本题考查程序流程图和有序链表的归并。
题目要求我们归并头指针分别为La和Lb的有序单链表,组成一个新的有序单链表 Lc,而Lc又是指向La的。首先,我们来了解一下单链表的结构。单链表中一般有两个域,一个是数据域,用来存放链表中的数据;另一个是指针域,用来存放指向下个结点的指针。其归并的过程应该是先比较链表La和Lb中第一个元素,将较小的从其链表中取出放到k中,再取下一个结点的值去比较,重复这个过程,直到一个链表被全部取完,再将另一个链表剩下的部分连接到Lc后面即可。
下面,我们来看程序流程图的内容。首先是用两个指针变量pa和pb分别指向La和Lb的当前待比较插入的结点,而pc指向Lc表中当前最后一个结点。再下面是一个条件判断语句,其作用是判断链表La和Lb是否为空,如果有一个为空,只要将另一个链表剩下的部分连接到Lc后面,程序应该就可以结束了。
第(1)空是条件判断语句的条件,根据我们上面的分析,再结合流程图下面的内容,我们可以知道,这个条件语句的作用是比较当前待插入的两个值的大小,而指针变量pa和pb分别指向La和Lb的当前待比较插入的结点,因此,此空的答案为 pa->data=pb->data。
第(2)空是在条件为真的情况下执行的语句,如果条件判断为真,应该将pa所指结点连接到pc所指结点后面,因此,pc所指结点的指针域应该存放pa所指结点的地址。所以,此空的答案为pc->next=pa。
第(3)空和第(4)空都是在条件为假的情况下执行的语句,如果条件为假,说明 pb所指结点的值小于pa所指结点的值,应该将pb所指结点连接到pc所指结点后面,图中已经实现这一功能,要我们完成的是在插入后的后继工作。由于pc指向的是Lc表中当前最后一个结点,在插入一个结点后,要修改pc的值。在将pb所指结点插入后,链表中的最后一个结点就是pb所指结点,第(3)空的答案应该为pc=pb。执行完这些功能后,指针pb应该要往后移动,即指向下一个结点,第(4)用来完成这个功能,所以答案为pb=pb->next。
在前面,我们已经讲到如果链表La和Lb有一个为空,只要将另一个链表剩下的部分连接到Lc后面即可。第(5)空就是用来完成这个功能的,但我们不知道具体是哪个链表为空,还需要判断,因此,此空答案为pc->next=pa?pa:pb。
第9题:
阅读下列说明和流程图,将应填入(n)处的语句写在对应栏内。
【说明】
有数组A(4,4),把1到16个整数分别按顺序放入A(1,1),…,A(1,4),A(2,1),…,A(2,4),A(3,1),…,A(3,4),A(4,1),…,A(4,4)中,下面的流程图用来获取数据并求出两条对角线元素之积。
【流程图】

(1)1,4,1 (2)1,4,1 (3)1 (4)s×A[i,i] (5)s×A[5-i,i] 解析:本题考查用程序流程图描述数组及求对角线的和。
题目要求把1到16个整数分别按顺序放入A(1,1),…,A(1,4),A(2,1),…,A(2,4), A(3,1),…,A(3,4),A(4,1),…,A(4,4)中,那么数组中的元素刚好构成一个方阵,用流程图求出这个方阵的对角线之积。下面来具体分析流程图。
第(1)空与第(2)空应该结合起来完成,它们都是一个循环判断语句的条件,从图中可以看出,如果这两个条件都成立,则读出当前数组中的元素值,根据题目要求,数组中的元素个数是每行4个每列4个,那么循环的上界应该是4,而下标是从1开始的,因此这两个空答案为1,4,1。
第(3)空是一个赋值语句,给变量s赋一个初值,从图中后面的语句不难看出s中存放的是求积的结果,那么在求积以前,s的值应该为1,因此此空答案为1。
第(4)空也是一个赋值语句,是在循环条件判断语句下,我们已经知道变量s中存放的是每次求积的结果,那么此空很明显是用来求积的,用当前取到的对角线元素乘以变量s中存放的值,因此此空答案为s×A[i,i]。
第(5)空和上一空非常相似,但它是用来求另外一条对角线的积的,它也是在一个循环下来实现的,这条对角线的元素位置与上面那条具有对称的特点,因此此空答案为s×A[5-i,i]。
第10题:
阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入对应栏内。
[说明]
下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。
设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中,n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在“aaaa”中只出现两次“aa”。
该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i为字符串A中当前正在进行比较的动态予串首字符的下标,j为字符串B的下标,k为指定关键词出现的次数。
[流程图]

0-k i+j i+m i+1 i 解析:本题考查用流程图描述算法的能力。
在文章中查找某关键词出现的次数是经常碰的问题。例如,为了给文章建立搜索关键词,确定近期的流行语,迅速定位文章的某个待修改的段落,判断文章的用词风格,甚至判断后半本书是否与前半本书是同一作者所写(用词风格是否一致)等,都采用了这种方法。
流程图最终输出的计算结果K就是文章字符串A中出现关键词字符串B的次数。显然,流程图开始时应将K赋值0,以后每找到一处出现该关键词,就执行增1操作K=K+1。
因此(1)处应填0→K。
字符串A和B的下标都是从0开始的。所以在流程图执行的开始处,需要给它们赋值0。接下来执行的第一个小循环就是判断A(i),A(i+1),…,A(i+j-1)是否完全等于B(0),B(1),…,B(m-1),其循环变量j=0,1,…,m-1。只要发现其中对应的字符有一个不相等时,该小循环就结束,不必再继续执行该循环。因此,该循环中继续执行的判断条件应该是A(i+j)=B(j)且jm。只要遇到A(i+j)≠B(j)或者j=m(关键词各字符都己判断过)就不再继续执行该循环了。因此流程图的(2)处应填州i+j。
许多考生在(2)处填i,当j增1变化后,仍然使用A(i)进行比较就不对了。因此,在检查循环程序段时应多走查一次循环。
如果(2)处整体的判断条件不成立,则该判断关键词的小循环结束。此时可能有两种情况。一是在j=0,1,…,m-1时全都成立A(i+j)=B(j)(找到了一处关键词),直到j=m时才结束小循环;二是在jm时就发现了字符不等的情况,这说明此处并不出现关键词。因此流程图中用jm来区分找到与没有找到关键词的两种情况。
对于j=m,已找到一处关键词的情况,显然应该执行k=k+1,对关键词出现次数的变量k进行增1计算。同时,为了继续进行以后的判断,应将字符串A的下标i右移m(这是因为题中假设关键词的出现不允许重叠)。因此(3)处应填写i+m,表示应该从已出现的关键词后面开始再继续进行判断。由于此时的j=m,书写i+j的答案也是正确的,但这不是程序员的好习惯,因为这不符合逻辑思维的顺势,在程序不断修改的过程中容易出错。不少考生在(3)处填写i+1,这意味着下次判断关键词将从A(i+1)开始,这就使关键词的出现有可能发生部分重叠的现象。
流程图中,对于jm的情况,表示刚才判断关键词时并非各个字符都完全相同,也就是说,刚才的判断结论是此处并没有出现关键词。即A(i)开始的子串并不是关键词。因此,下次判断关键词应该以A(i+1)开始,即(4)处应填i+1。
在下次判断关键词之前还应该判断是否全文已经判断完。最后一次小循环判断应该是对A(n-m),A(n-m+1),…,A(n-1)的判断。下标n-m来自从n-1倒数m个数。可以先试验写出A(n-m),A(n-m+1),…,A(n-1),再判断其个数是否为m。经检查,个数为(n-1)-(n-m)+1=m个,所以这是正确的。也可以用例子来检查次数是否正确。检查次数是程序员的基本功,数目的计算很容易少一个或多一个。
既然最后一次判断关键词应该是对A(n-m),A(n-m+1),…,A(n-1)的判断,即对i=n-m进行的小循环判断,所以当i>n-m时就应该停止大循环,停止再查找关键词了。